Research
Our pioneering research has been recognized in top-tier publications across AI (TPAMI, IJCV, NeurIPS, ICLR, CVPR, ICCV, ECCV), robotics (ICRA, IROS), and interdisciplinary fields (Cell Patterns, CACIE, BIB), reflecting our commitment to advancing science through impactful and innovative contributions.
Highlighted

RM-RL: Role-Model Reinforcement Learning for Precise Robot Manipulation
ICRA 2026
·
22 Jan 2026
·
arxiv:2510.15189
Real-world RL framework that uses a role-model strategy to label online samples for offline supervised replay, achieving millimeter-level precision in robot manipulation.
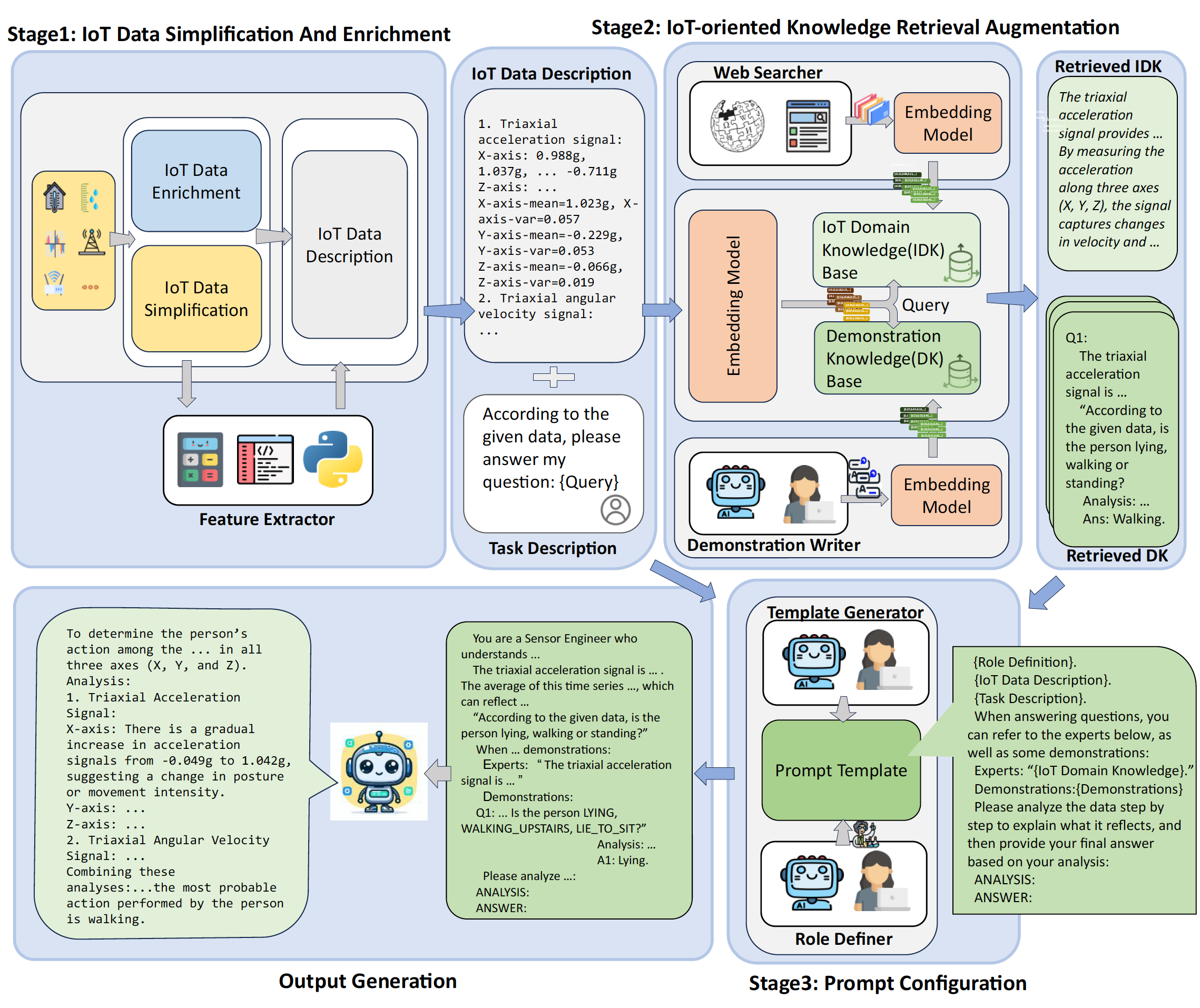
IoT-LLM: A framework for enhancing large language model reasoning from real-world sensor data
Patterns, Cell Press
·
10 Jan 2026
·
doi:10.1016/j.patter.2025.101429
A RAG-enhanced framework for enhancing LLM reasoning from real-world IoT sensor data across diverse tasks.

REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
ICLR 2026
·
22 Jan 2026
·
arXiv:2505.10872
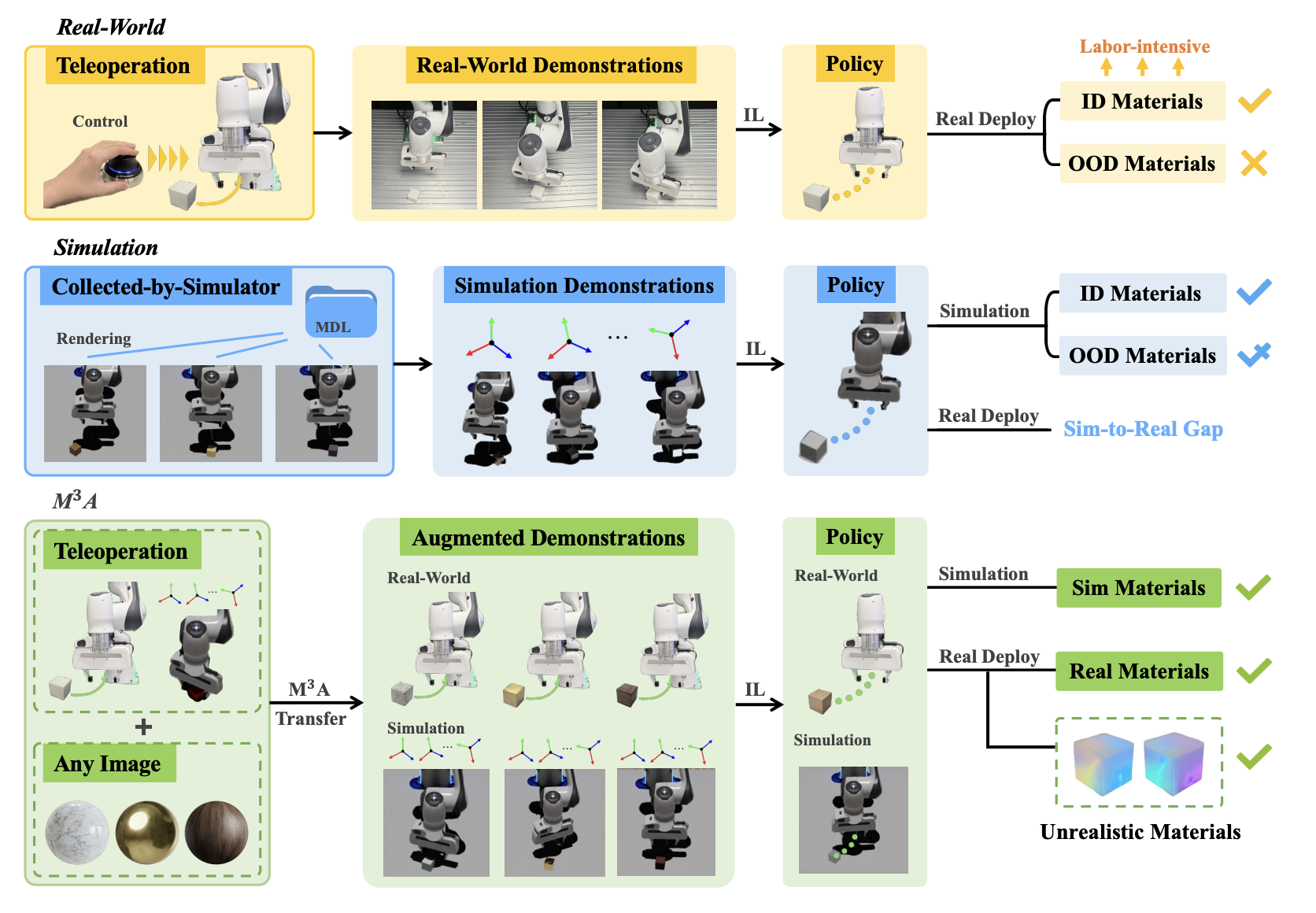
$\mathbf{M^3A}$ Policy: Mutable Material Manipulation Augmentation Policy through Photometric Re-rendering
CVPR 2026 (Findings)
·
23 Feb 2026
·
arxiv:2512.01446
A photometric re-rendering framework for material-generalized robotic manipulation via computational photography.

When Robots Should Say "I Don't Know": Benchmarking Abstention in Embodied Question Answering
CVPR 2026
·
23 Feb 2026
·
arxiv:2512.04597
First benchmark for evaluating abstention ability of embodied agents when facing ambiguous human queries.
All
2026
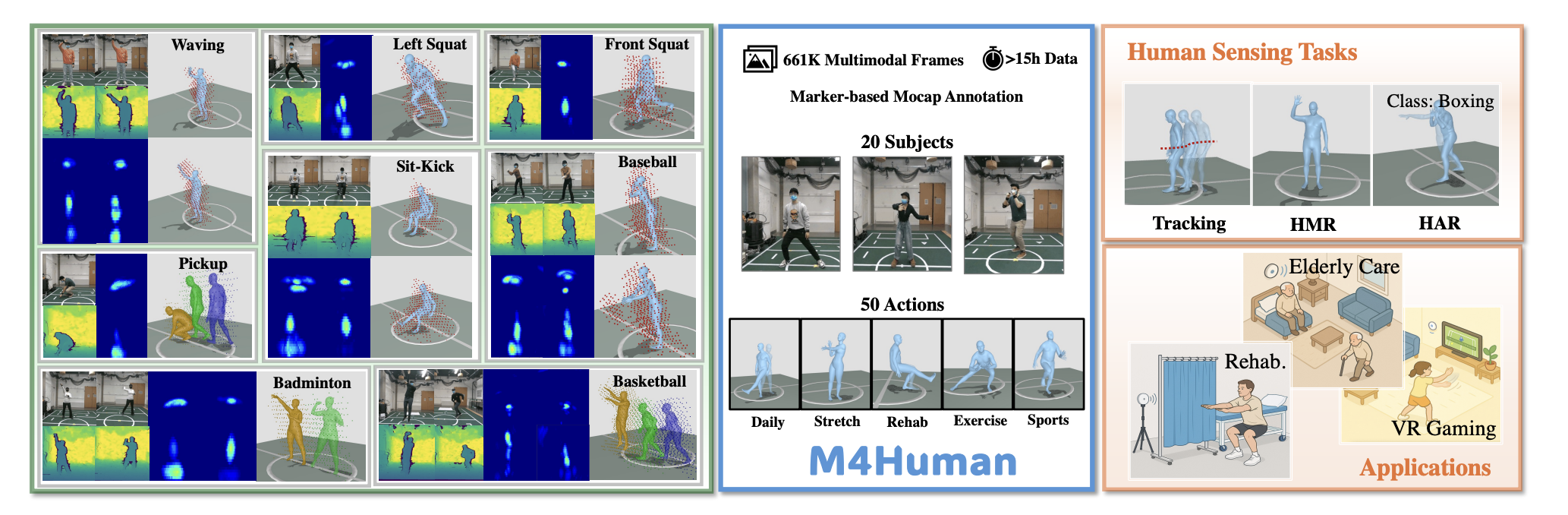
M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
CVPR 2026
·
23 Feb 2026
·
arxiv:2512.12378
The largest multimodal mmWave radar benchmark (661K frames) for high-fidelity human mesh reconstruction.
When Robots Should Say "I Don't Know": Benchmarking Abstention in Embodied Question Answering
CVPR 2026
·
23 Feb 2026
·
arxiv:2512.04597
First benchmark for evaluating abstention ability of embodied agents when facing ambiguous human queries.
$\mathbf{M^3A}$ Policy: Mutable Material Manipulation Augmentation Policy through Photometric Re-rendering
CVPR 2026 (Findings)
·
23 Feb 2026
·
arxiv:2512.01446
A photometric re-rendering framework for material-generalized robotic manipulation via computational photography.

RF-MatID: Dataset and Benchmark for Radio Frequency Material Identification
ICLR 2026
·
22 Jan 2026
·
arxiv:2601.20377
First open-source large-scale wide-band RF dataset and benchmark for fine-grained material identification.
REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
ICLR 2026
·
22 Jan 2026
·
arXiv:2505.10872
RM-RL: Role-Model Reinforcement Learning for Precise Robot Manipulation
ICRA 2026
·
22 Jan 2026
·
arxiv:2510.15189
Real-world RL framework that uses a role-model strategy to label online samples for offline supervised replay, achieving millimeter-level precision in robot manipulation.
IoT-LLM: A framework for enhancing large language model reasoning from real-world sensor data
Patterns, Cell Press
·
10 Jan 2026
·
doi:10.1016/j.patter.2025.101429
A RAG-enhanced framework for enhancing LLM reasoning from real-world IoT sensor data across diverse tasks.
2025
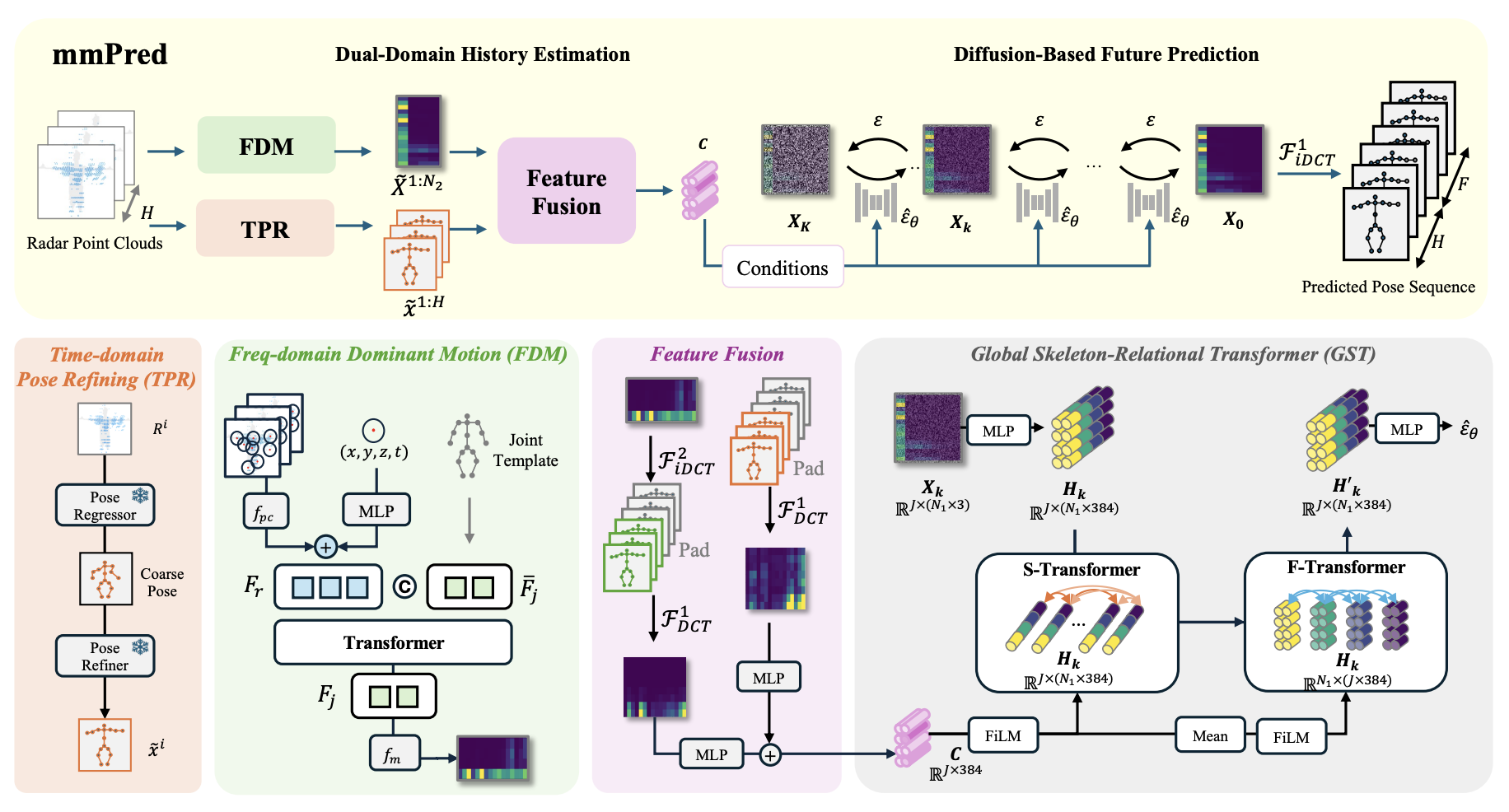
mmPred: Radar-based Human Motion Prediction in the Dark
AAAI 2026
·
01 Dec 2025
·
arxiv:2512.00345
First diffusion-based framework for radar-based human motion prediction, robust under adverse environments.
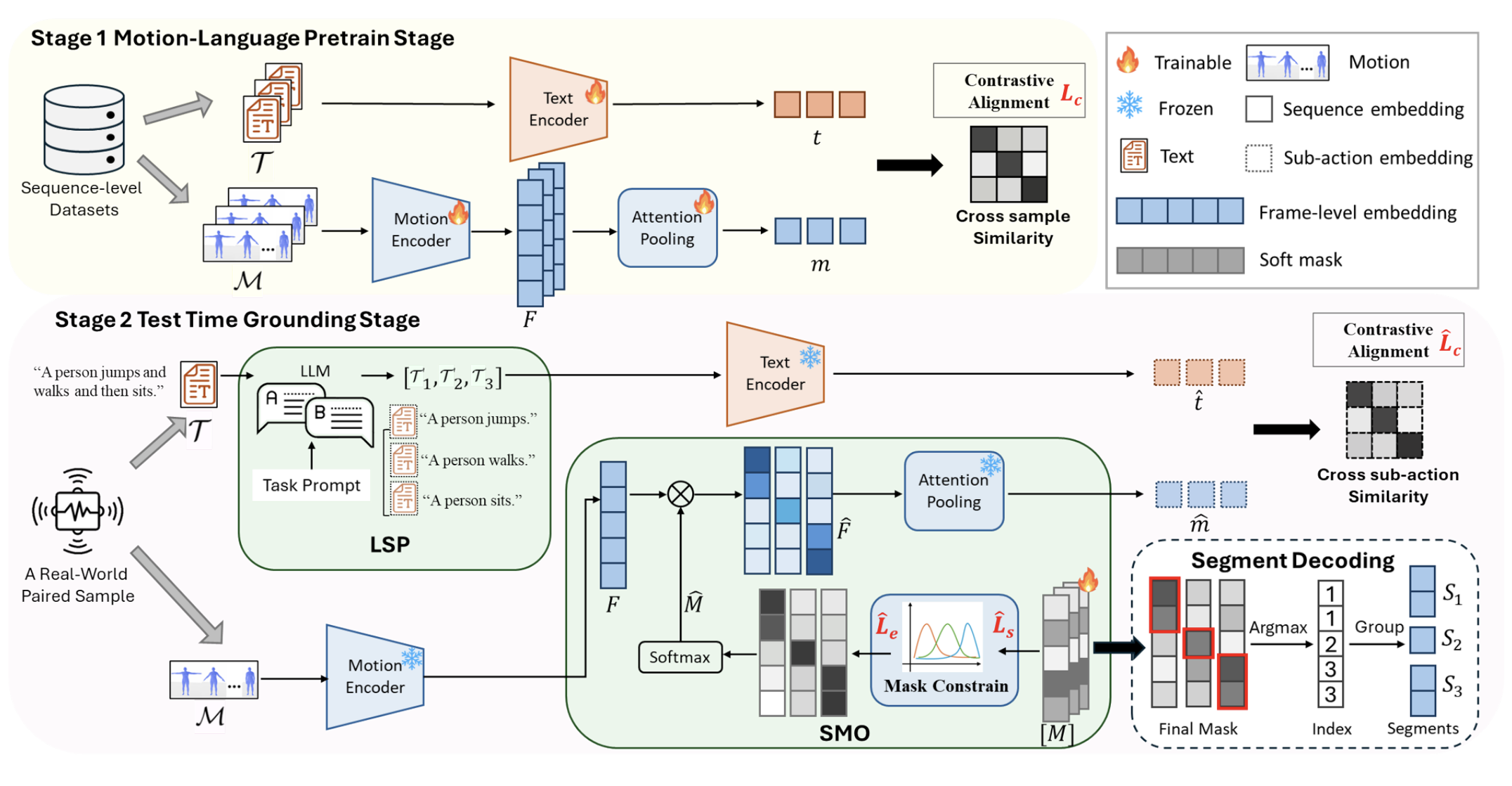
Zero-Shot Open-Vocabulary Human Motion Grounding with Test-Time Training
AAAI 2026
·
01 Nov 2025
·
arxiv:2511.15379
A zero-shot framework for open-vocabulary human motion grounding via LLM-guided decomposition and soft masking optimization.
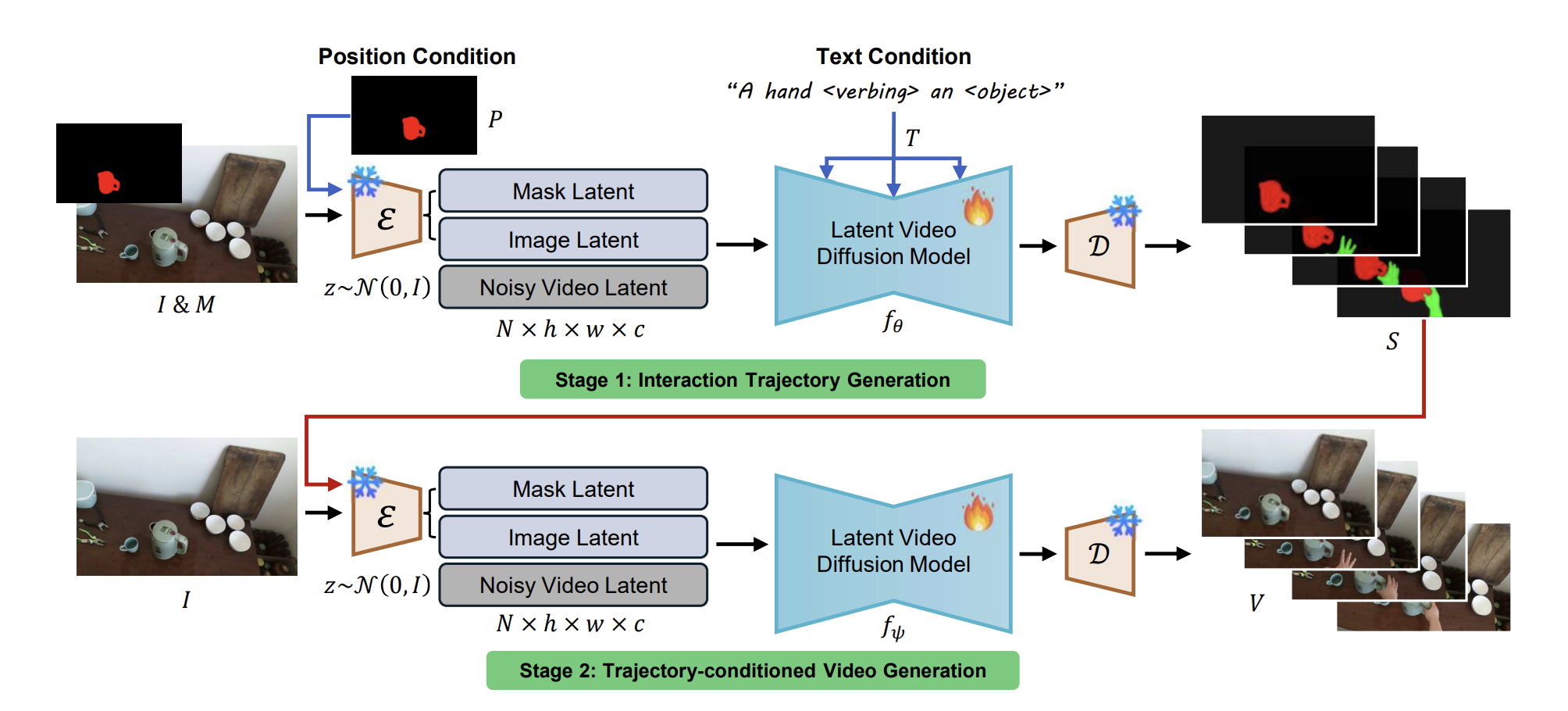
Mask2IV: Interaction-Centric Video Generation via Mask Trajectories
AAAI 2026
·
01 Nov 2025
·
arxiv:2510.03135
A two-stage framework for interaction-centric video generation that predicts mask trajectories for both actors and objects.

Interactive Test-Time Adaptation with Reliable Spatial-Temporal Voxels for Multi-Modal Segmentation
European Conference on Computer Vision (ECCV), 2024
·
07 Oct 2025
·
arxiv:2403.06461

HoloLLM: Multisensory Foundation Model for Language-Grounded Human Sensing and Reasoning
NeurIPS 2025
·
23 May 2025
·
arXiv:2505.17645
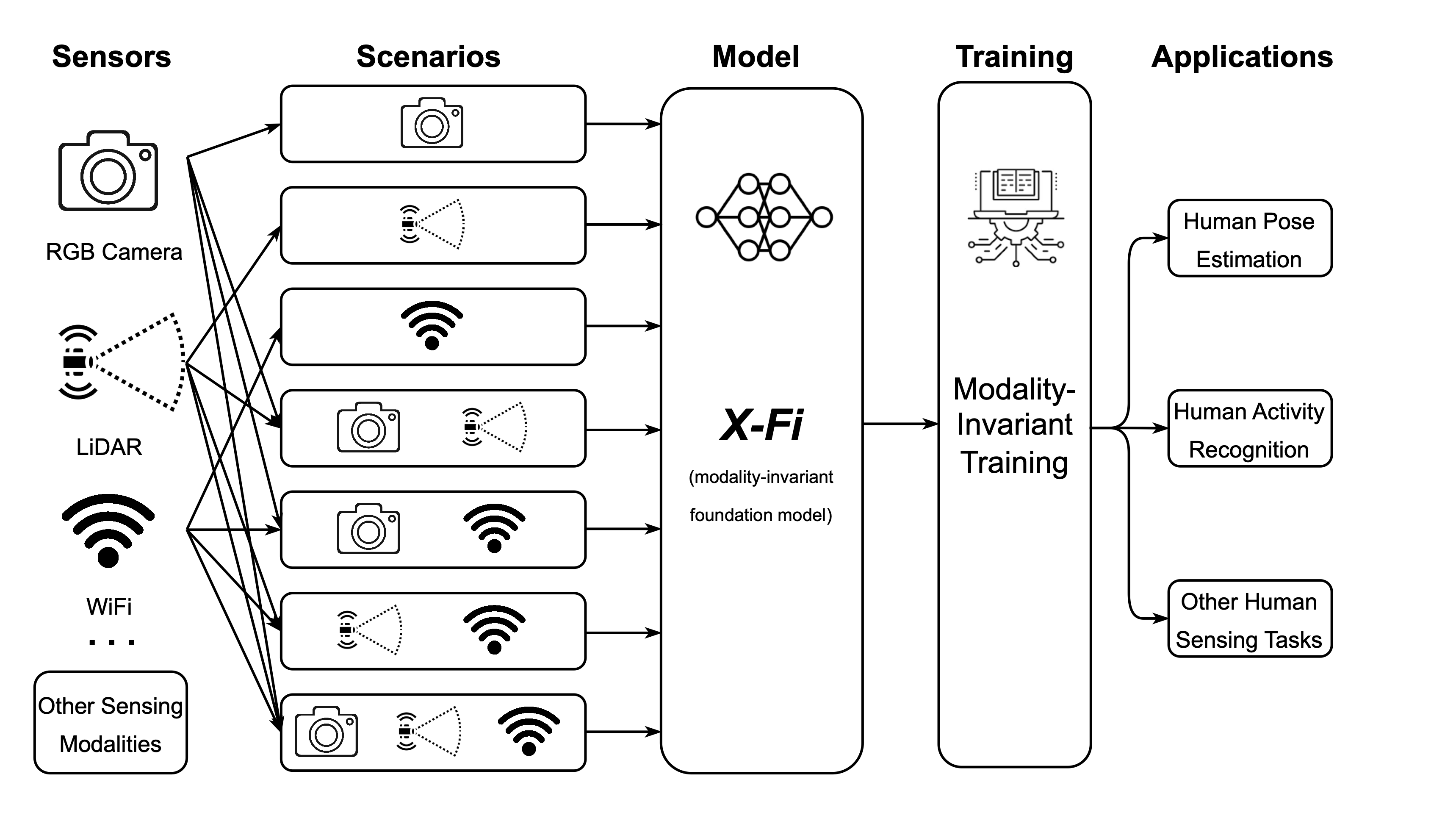
X-Fi: A Modality-Invariant Foundation Model for Multimodal Human Sensing
ICLR 2025
·
22 Jan 2025
·
arXiv:2410.10167
2024

Video Unsupervised Domain Adaptation with Deep Learning: A Comprehensive Survey
ACM Computing Surveys
·
01 Oct 2024
·
doi:10.1145/3679010

MoPA: Multi-Modal Prior Aided Domain Adaptation for 3D Semantic Segmentation
2024 IEEE International Conference on Robotics and Automation (ICRA)
·
13 May 2024
·
doi:10.1109/ICRA57147.2024.10610316

Can We Evaluate Domain Adaptation Models Without Target-Domain Labels?
ICLR 2024
·
01 Jan 2024
·
doi:10.48550/arXiv.2305.18712
2023

Going Deeper into Recognizing Actions in Dark Environments: A Comprehensive Benchmark Study
International Journal of Computer Vision
·
08 Nov 2023
·
doi:10.1007/s11263-023-01932-5

Multi-Modal Continual Test-Time Adaptation for 3D Semantic Segmentation
2023 IEEE/CVF International Conference on Computer Vision (ICCV)
·
01 Oct 2023
·
doi:10.1109/ICCV51070.2023.01724

MetaFi++: WiFi-Enabled Transformer-Based Human Pose Estimation for Metaverse Avatar Simulation
IEEE Internet of Things Journal (IoT-J)
·
15 Aug 2023
·
doi:10.1109/JIOT.2023.3262940
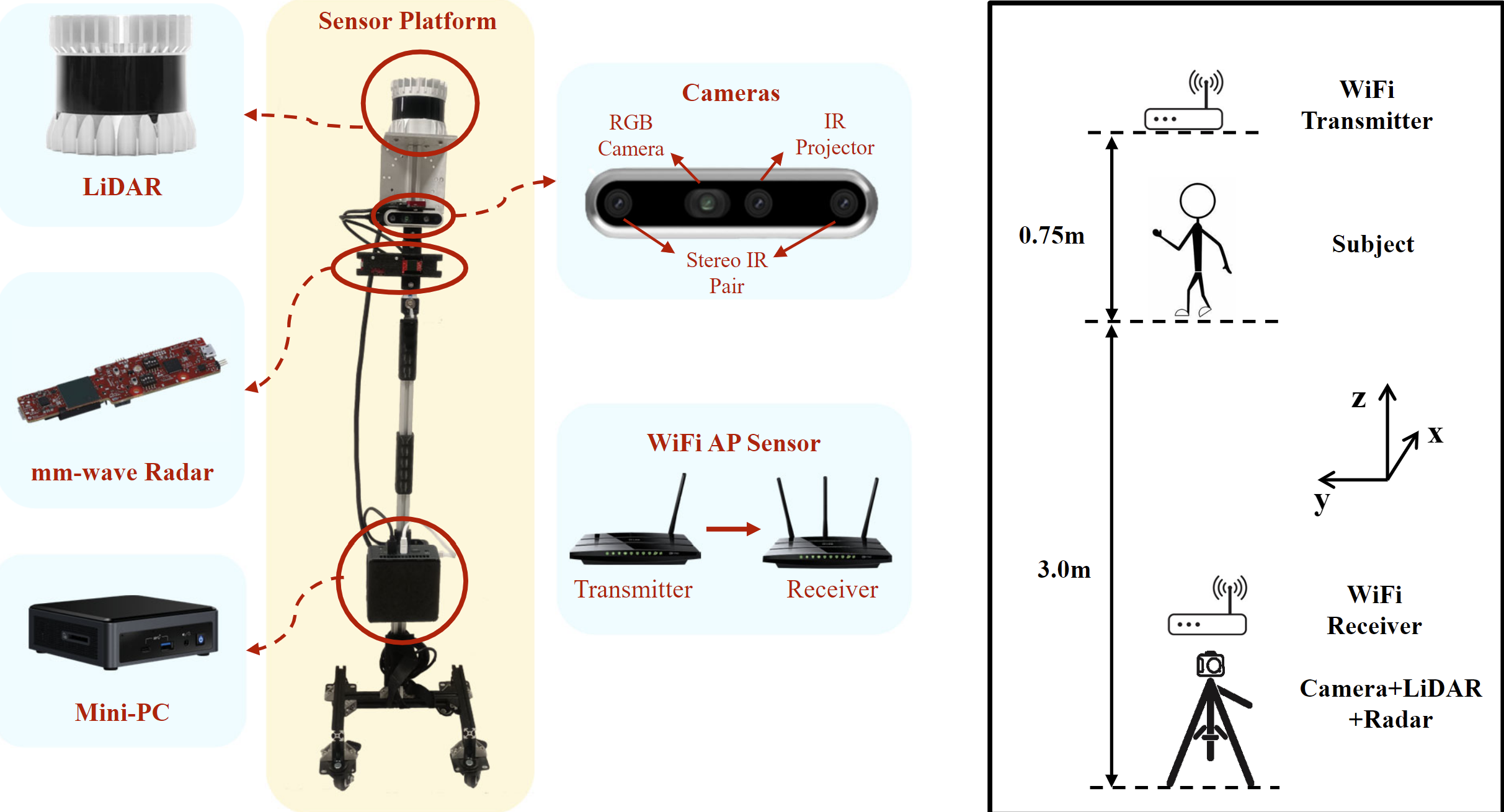
MM-Fi: Multi-Modal Non-Intrusive 4D Human Dataset for Versatile Wireless Sensing
NeurIPS 2023 Datasets and Benchmarks Track
·
11 May 2023
·
arxiv:2305.10345
The world-first multi-modal non-intrusive 4D human dataset (RGB, Depth, LiDAR, mmWave, WiFi).

SenseFi: A library and benchmark on deep-learning-empowered WiFi human sensing
Patterns, Cell Press
·
10 Mar 2023
·
doi:10.1016/j.patter.2023.100703
The world-first open-source benchmark on deep learning-empowered WiFi sensing.

Divide to Adapt: Mitigating Confirmation Bias for Domain Adaptation of Black-Box Predictors
ICLR 2023
·
01 Jan 2023
·
arXiv:2205.14467